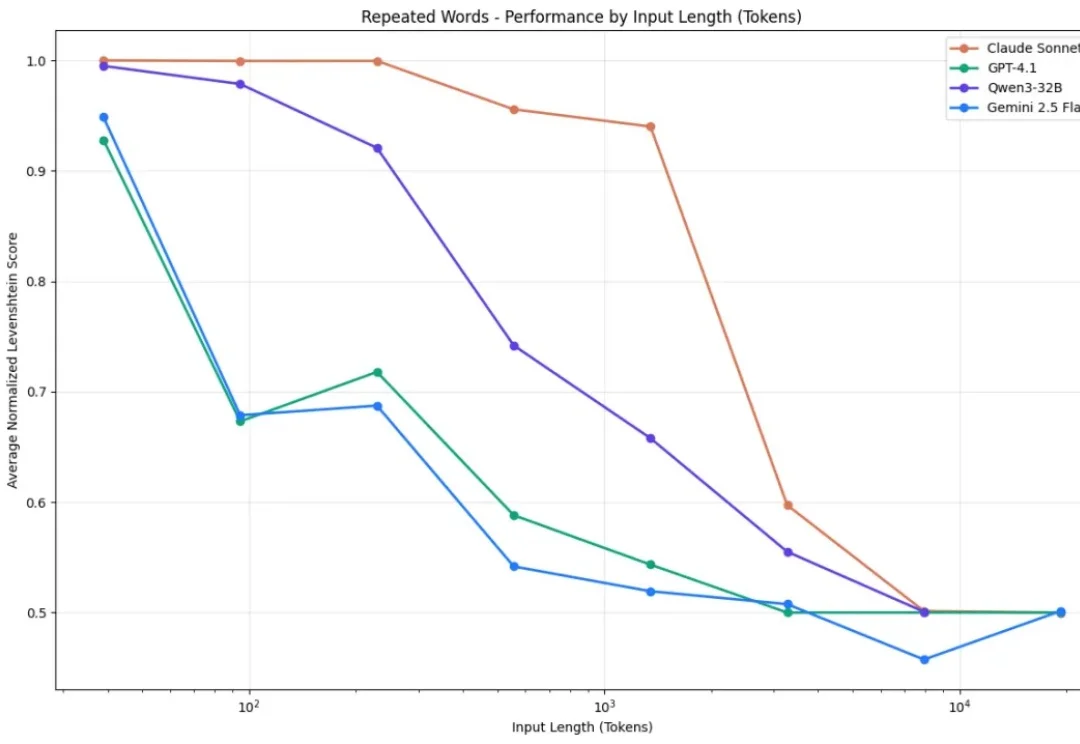
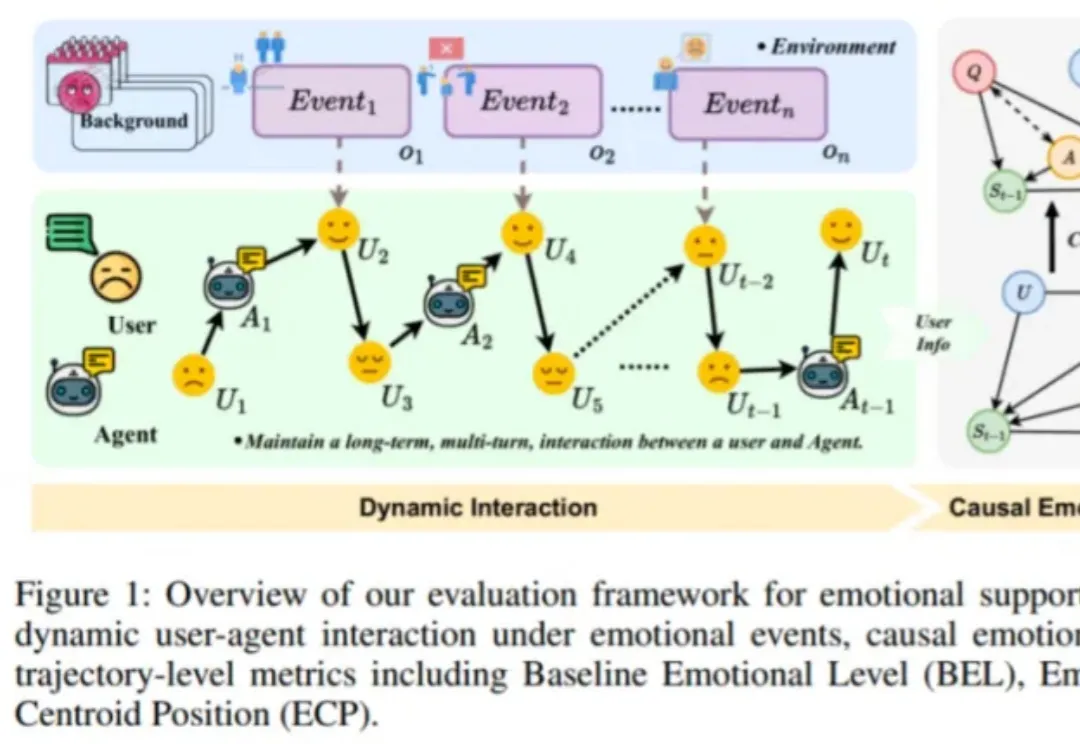
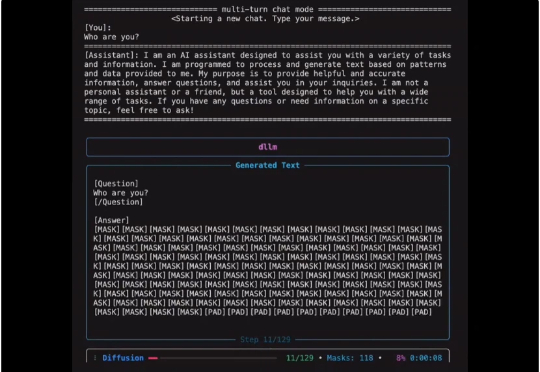
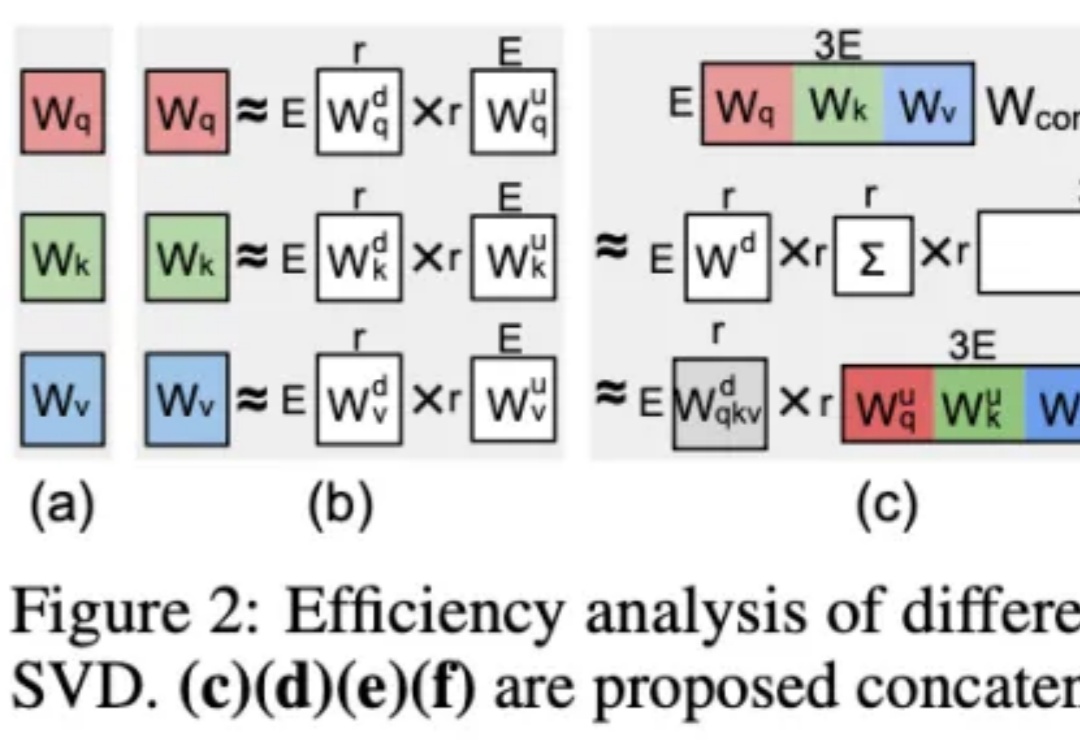
刚刚,DeepSeek 再发梁文锋署名新论文:Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
刚刚,DeepSeek 再发梁文锋署名新论文:Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models今天凌晨,喜欢闷声做大事的 DeepSeek 再次发布重大技术成果,在其 GitHub 官方仓库开源了新论文与模块 Engram,论文题为 “Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models”, 梁文锋再次出现在合著者名单中。
来自主题: AI资讯
11907 点击 2026-01-13 07:59